So idea #2 is to do with flavour. There needs to be some way to directly sample what’s on the other side of a link, to get the flavour of a page before deciding to stuff it down our browser gullet. So let’s see, to get the taste component we need a small number of attributes which are universal across all pages.
I suggest:
- is it an outward-linking page, like a contents page, or an inwardly focused page like an essay?
- is it updated a lot?
- is the text more 3rd person, like a corporate or academic page, or more a 1st person thing: subjective, like a journal
- lastly, the pagerank.
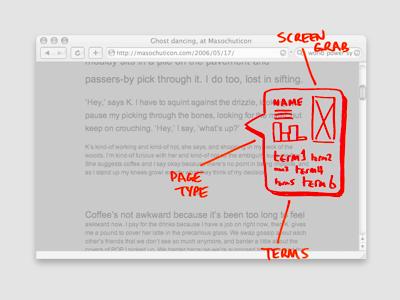
Okay, that’s taste. The sight is simply the surface of the page: a screenshot and the title of the page.
Now the smell of the page. We’ll do that with a term extractor, which gets the distinctive words and phrases that describe this page. We’ll also want to know how strong these terms are—a single overwhelming phrase means this page is all about that topic; multiple weaker phrases mean this is a multi-subject page.
Show all of these together whenever you mouse-over a link: that’s the flavour.
We could implement the “feeling of the right taste” by letting you set acceptors to certain tastes: you might be looking for essays of good-standing. Those tastes will be highlighted.